
สวัสดีคร้บ วันนี้ผมมี Worfklow ผมมีอีก 1 n8n workflow มาแชร์ให้ทุกคนกันครับผม เป็น workflow ที่มีคนถามเข้ามาเยอะมากกกกกกก ทั้งจากคอมเมนต์ใน youtube, facebook หรือบางทางอีเมล์มาเลยก็มี วันนี้ก็เลยถือโอกาสทำแล้วก็มาแชร์ให้ทุกคน หวังว่าจะมีประโยชน์ไม่มากก็น้อยนะครัผม
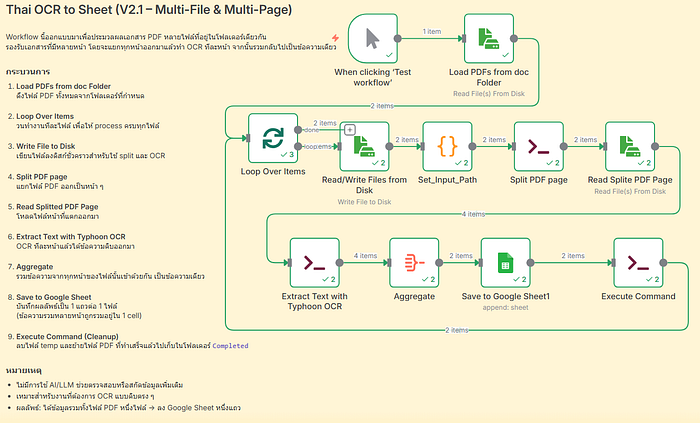
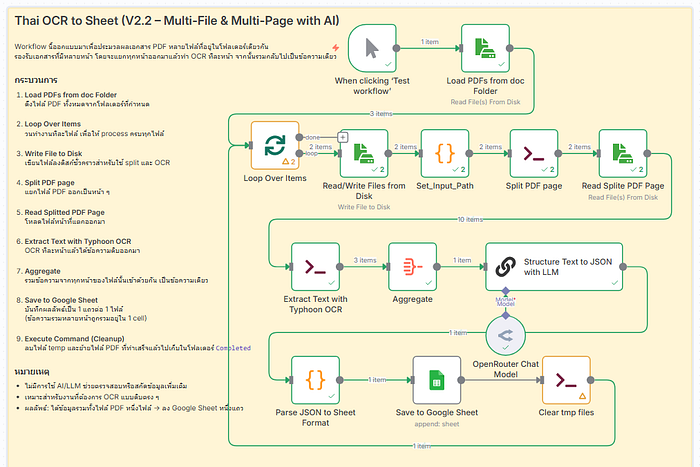
โดย workflow นี้นะครับ เป็นการอัปเกรด workflow จากครั้งที่แล้วที่เราใช้ TyphoonOCR อ่านเอกสาร pdf ภาาาไทย แล้วบันทึกลง google sheet แต่ใน workflow แรก เราสามารถทำได้ทีละแผ่นเนื้องจาก TyphoonOCR รับเอกสารครั้งละ 1 page ครับผม แต่สำหรับ Workflow ใหม่ในวันนี้จะเป็นการทำให้เราสามารถใช้กับเอกสาร PDF ที่มีหลายหน้า ได้ครับผม
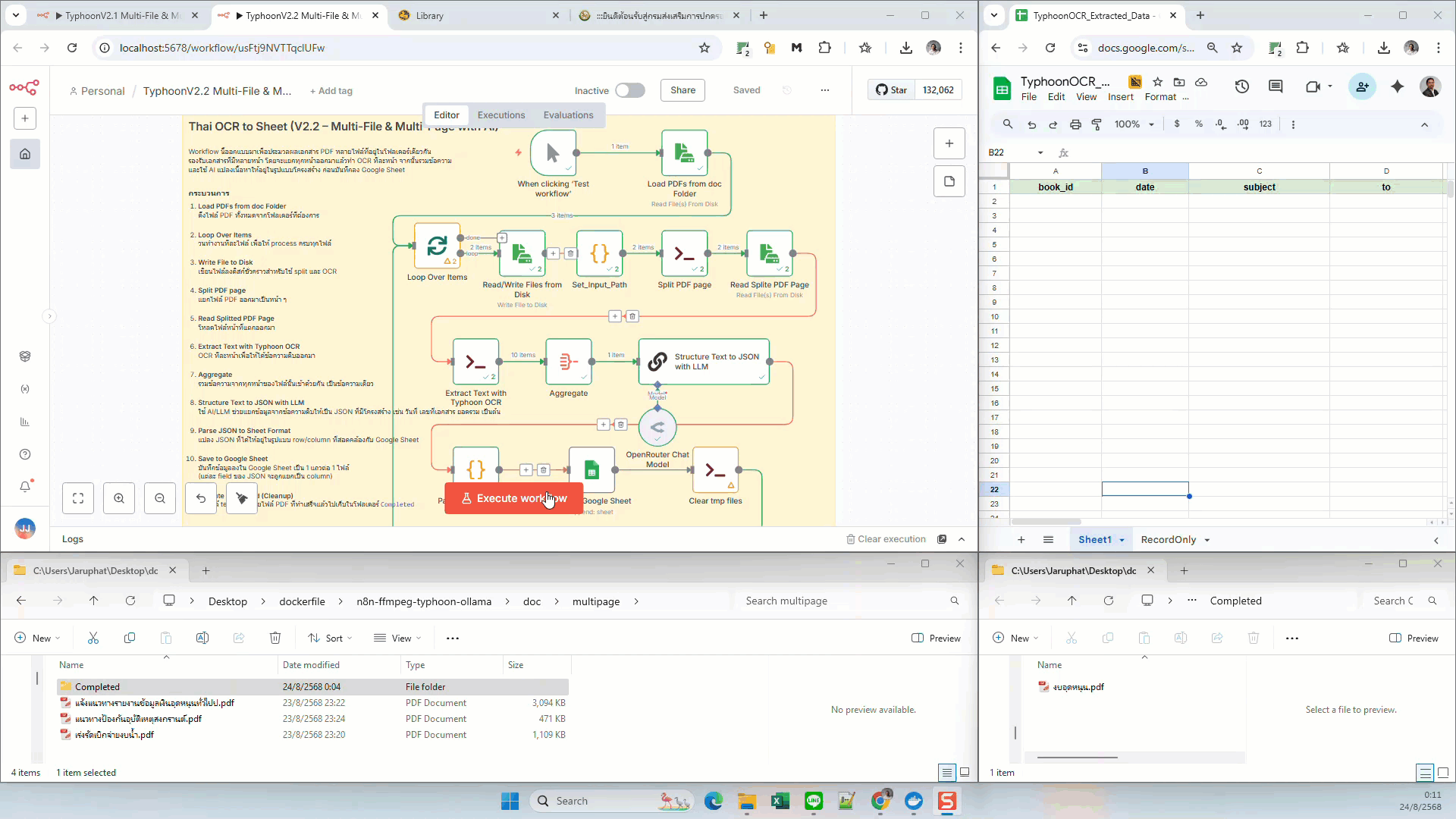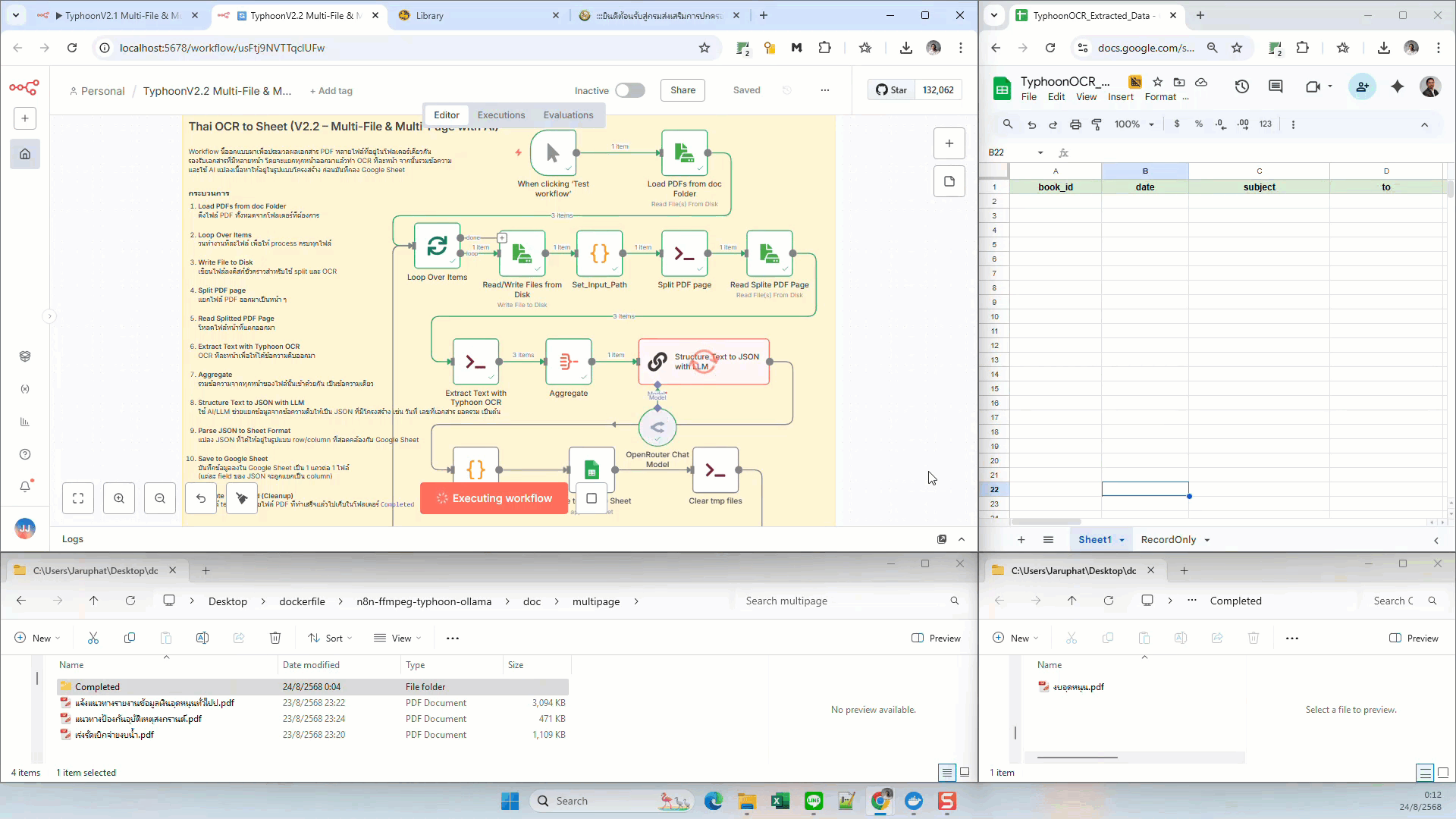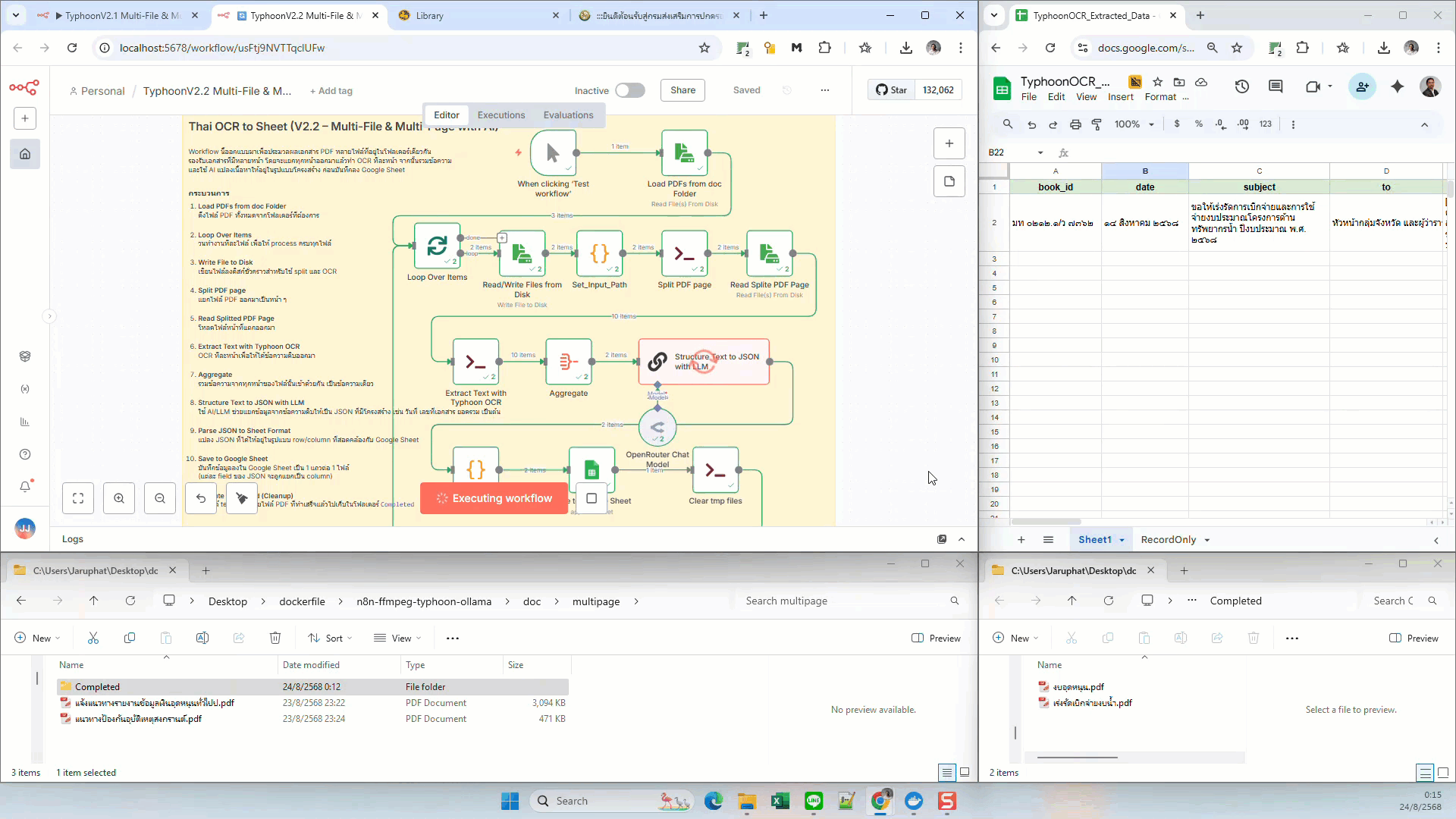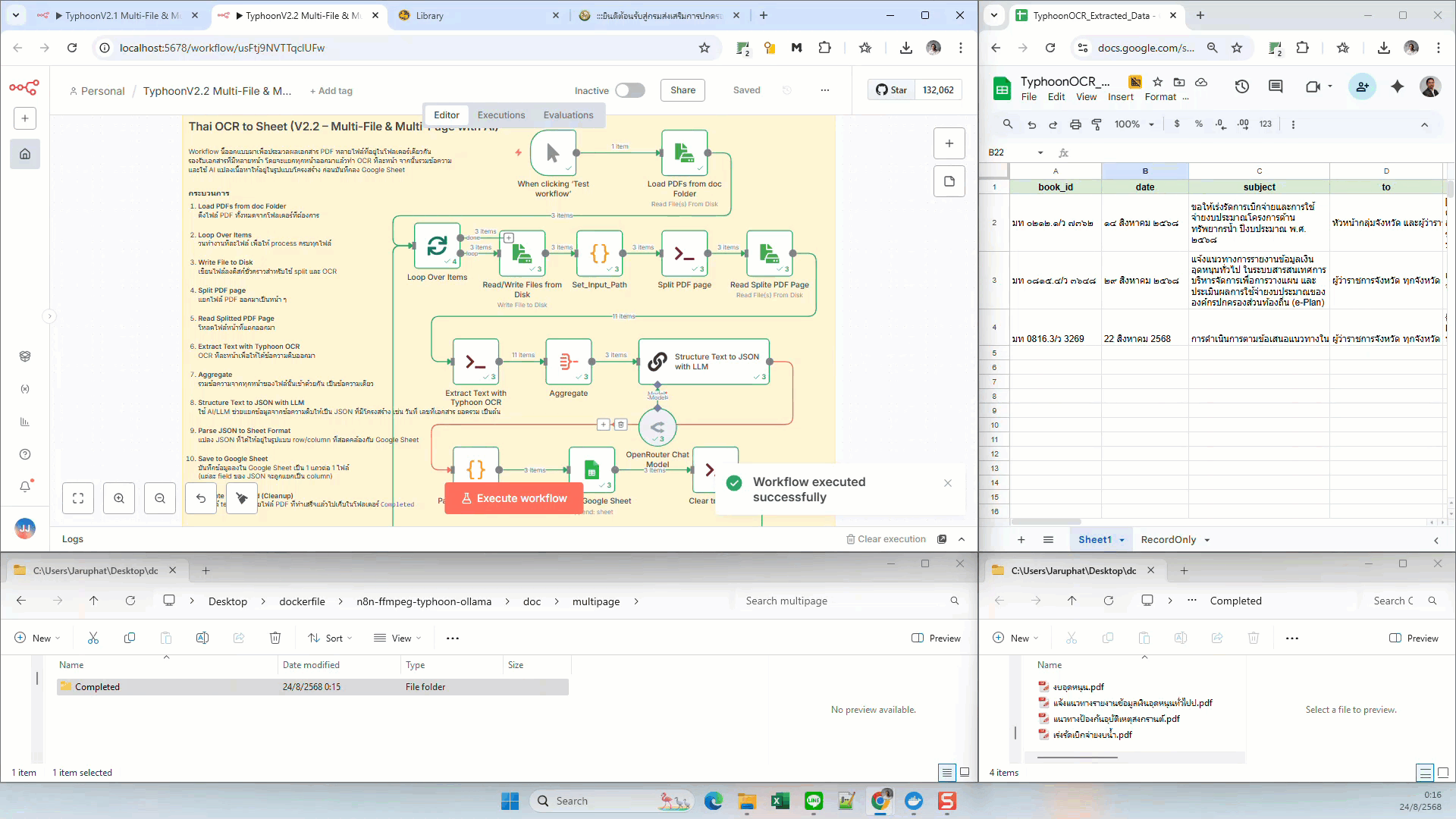
Thai OCR to Sheet (Multi-File & Multi-Page with AI)
- Load PDFs from Folder — โหลดไฟล์ PDF หลายไฟล์จากโฟลเดอร์เดียวกัน
- Loop Over Items — วนทำงานทีละไฟล์
- Write File to Disk — เขียนไฟล์ลง disk ชั่วคราว
- Split PDF page — แยกไฟล์ออกเป็นหลายหน้า
- Read Splitted PDF Page — โหลดไฟล์แต่ละหน้า
- Extract Text with Typhoon OCR — OCR ภาษาไทยทีละหน้า
- Aggregate — รวมข้อความจากทุกหน้าเป็นก้อนเดียว
- Structure Text to JSON with LLM — ส่งข้อความรวมเข้าหา AI เพื่อแปลงเป็น JSON
- Parse JSON to Sheet Format — แปลง JSON ให้อยู่ในฟอร์แมตของ Google Sheet
- Save to Google Sheet — บันทึกเป็น 1 แถวต่อ 1 ไฟล์ ข้อมูลแต่ละ field แยกเป็น column
- Execute Command (Cleanup) — เคลียร์ไฟล์ temp และย้ายไฟล์ที่ทำเสร็จแล้วไปไว้ใน
Completed
การตั้งค่าโหนดสำคัญ
Load PDFs from Folder
- Path:
/doc/multipage/*.pdf - ได้หลาย items (หนึ่งไฟล์ = หนึ่ง item)
Loop Over Items / Split In Batches
- Batch size = 1 เพื่อวนทำงานทีละไฟล์
Write File to Disk
- Input Binary Field:
data(หรือ field binary ที่ได้จากโหนดก่อนหน้า) - File Path:
/doc/tmp/in.pdf - เปิด Overwrite = true
Split PDF page (Execute Command)
ใช้ pdfinfo + pdfseparate เพื่อนับจำนวนหน้าและแยกไฟล์
sh -lc '
set -e
IN="{{ $json.inputPath }}"
OUT="/doc/tmp/pages"
rm -rf "$OUT" && mkdir -p "$OUT"
# นับจำนวนหน้า (ต้องมี poppler-utils)
PAGES=$(pdfinfo "$IN" 2>/dev/null | awk -F": *" "/^Pages/{print \$2}")
[ -n "$PAGES" ] || { echo "Cannot detect page count for: $IN" >&2; exit 1; }
pdfseparate -f 1 -l "$PAGES" "$IN" "$OUT/page_%d.pdf"
ls -1 "$OUT"/page_*.pdf
'
Read Splitted PDF Page
- Path:
/doc/tmp/pages/*.pdf - Binary Property:
page - ได้หลาย items (1 หน้า = 1 item)
Extract Text with Typhoon OCR (HTTP Request)
python -c "import sys, os; os.environ['TYPHOON_OCR_API_KEY'] = '<อย่าลืมเปลี่ยนตรงนี้นะครับ TyphoonAPI>'; from typhoon_ocr import ocr_document; sys.stdout.reconfigure(encoding='utf-8'); input_path = sys.argv[1]; text = ocr_document(input_path); print(text)" "/doc/tmp/pages/{{$json["fileName"]}}"
จัด Format JSON เข้า sheet
รวมเอกสารจาก LLM เข้า format สำหรับ google sheet
const raw = $json["text"];
// 1. ลบ ```json และ ``` ที่ LLM อาจใส่มา
const cleaned = raw.replace(/```json\n?|```/g, "").trim();
let parsed;
try {
// 2. แปลงเป็น object
parsed = JSON.parse(cleaned);
} catch (err) {
throw new Error("JSON parsing failed: " + err.message + "\n\nRaw text:\n" + cleaned);
}
// 3. หาก contact เป็น object แยก field ออกมา
const contact = parsed.contact || {};
return {
book_id: parsed.book_id || "",
date: parsed.date || "",
subject: parsed.subject || "",
to: parsed.to || "",
attach: parsed.attach || "",
detail: parsed.detail || "",
signed_by: parsed.signed_by || "",
signed_by2: parsed.signed_by2 || "",
contact_phone: contact.phone || "",
contact_email: contact.email || "",
contact_fax: contact.fax || "",
download_url: parsed.download_url || ""
};
Save to Google Sheet
- Operation: Append
- Range: เช่น
OCR!A:C - Columns:
file_name,text,processed_at - Values:
={{ $json.baseName }},={{ $json.combined_text }},={{ (new Date()).toISOString() }}
Execute Command (Cleanup)
ลบไฟล์ temp และย้ายไฟล์ต้นฉบับไป Completed
sh -lc '
set -e
# ลบโฟลเดอร์ temp ที่ใช้เก็บไฟล์ที่ split
rm -rf /doc/tmp/pages
# ย้ายไฟล์ต้นฉบับ (input PDF) ไปเก็บไว้ใน Completed
mkdir -p /doc/multipage/Completed
# ใช้ $json.fileName ของ node ต้นทาง (Load PDFs from doc Folder)
# ถ้า fileName เป็น path อยู่แล้ว ให้ basename ออกมาก่อน
src="/doc/multipage/{{ $('Load PDFs from doc Folder').item.json.fileName }}"
dst="/doc/multipage/Completed/{{ $('Load PDFs from doc Folder').item.json.fileName }}"
mv "$src" "$dst"
echo "Moved $src → $dst"
'
สรุป
เวอร์ชันนี้เป็นอีกก้าวที่ช่วยลดงาน manual ได้เยอะ จาก OCR ดิบ ๆ มาเป็นข้อมูลที่พร้อมใช้ทันทีด้วย AI และการแก้ปัญหาจำกัดของ Typhoon OCR ที่ทำได้ทีละหน้า โดยการ split ไฟล์ PDF ก่อน OCR
ในอนาคต ผมอาจเพิ่มการ validate ข้อมูล เช่น ตรวจสอบ format ของวันที่ หรือการ cross check กับฐานข้อมูลลูกค้า เพื่อให้กระบวนการนี้ไปได้ไกลกว่าแค่ OCR + Save to Sheet
ใครที่สนใจลองทำ สามารถใช้ n8n + Typhoon OCR + LLM ตัวไหนก็ได้ มาประกอบร่างกันตาม flow นี้ได้เลยครับ
บทส่งท้าย
หวังว่าบทความนี้จะเป็นประโยชน์สำหรับผู้ที่สนใจพัฒนา n8n นะครับผม บางอย่างอาจจะต้องเอาไปปรับเพิ่มเติม แต่หวังว่า อาจจะเอาไปเป็นไอเดียเบื้องต้นได้ครับผม
ขอบคุณทุกคนมากนะครับที่อ่านมาถึงตรงนี้ ฝากติดตามผมในช่องทางอื่นด้วยนะครับ
🔵Facebook Page: https://www.facebook.com/JaruphatJ 📲
🔴Youtube Channel: https://www.youtube.com/@JaruphatJ 🎥
💡 อย่าลืมกด Like 👍, Subscribe 🔔 และ Comment 💬 เพื่อเป็นกำลังใจให้ผมด้วยนะครับ! 🚀
📎 External Links
- Typhoon OCR
- Documentation
- n8n Template: Process Thai Documents with TyphoonOCR & AI to Google Sheets (Multi-Page PDF)